

« Les entreprises veulent accélérer l’adoption de l’IA mais avec le contrôle, la prédictibilité et la gouvernance intégrés »
Sumeet Arora, directeur produit chez Teradata
L’essor fulgurant des modèles de langage internes (LLM interne ) transforme profondément les entreprises. Cette évolution s’accompagne toutefois de nouveaux défis en matière de souveraineté numérique et de conformité réglementaire. En 2026, réussir son virage IA passe de plus en plus par le déploiement de LLM internes sur ses propres serveurs.
Cette approche permet d’innover tout en protégeant les données sensibles et en respectant des cadres comme le Règlement général sur la protection des données. Elle répond aussi aux exigences croissantes en matière de gouvernance et de contrôle des systèmes d’IA.
De l’architecture technique aux enjeux de sécurité, en passant par les contraintes réseau, héberger un modèle en interne devient un choix stratégique. Que ce soit au Maroc, en France ou ailleurs, cette approche permet de concilier performance, maîtrise des données et conformité réglementaire.
Pourquoi opter pour un LLM interne en 2026 ? (Souveraineté et conformité)
Les chiffres confirment la tendance : selon une enquête de 2024, 45 % des organisations envisagent désormais l’on‑premise pour leurs nouvelles applications IA, et 42 % ont rapatrié des workloads d’IA du cloud en raison de préoccupations de sécurité et de confidentialité.
Garder le contrôle de ses données est devenu un impératif stratégique pour les entreprises. La donnée est aujourd’hui un actif critique. Le déploiement d’un LLM interne répond directement à cet enjeu. Il garantit que les informations sensibles restent confinées dans le périmètre sécurisé de l’organisation.
Contrairement aux solutions SaaS ou aux API externes, aucun flux de données confidentielles n’est exposé à des tiers. Cela réduit fortement les risques de fuite, d’exploitation ou de mauvaise utilisation des données.

Cette approche facilite également la conformité réglementaire. Elle répond notamment aux exigences du Règlement général sur la protection des données. Ce cadre impose un contrôle strict sur la localisation, le traitement et la gouvernance des données personnelles.
Avec un LLM hébergé en interne, les entreprises peuvent tracer précisément les usages. Elles contrôlent les accès et peuvent démontrer leur conformité lors d’audits.
Par exemple, lorsqu’un collaborateur interroge un modèle interne, aucune donnée client n’est transmise sur Internet. Cela rassure à la fois les équipes juridiques et les responsables sécurité.
Au-delà de la conformité, cette stratégie renforce la souveraineté numérique. Les données restent hébergées localement, au Maroc ou dans des infrastructures européennes. Cela limite les risques liés aux transferts transfrontaliers et aux juridictions étrangères.
Cette approche devient un argument fort auprès des clients et partenaires. Ils sont de plus en plus sensibles à la protection de leurs informations.
Enfin, un LLM interne contribue à structurer les usages de l’IA au sein de l’entreprise. Il offre un cadre sécurisé et maîtrisé. Il reste aligné avec les politiques internes. Ainsi, l’IA devient un levier de performance plutôt qu’une source de risque.
Architecture d’un LLM interne : infrastructure et intégration
Architecture technique et infrastructure d’un LLM interne
Mettre en place un LLM interne requiert une architecture technique robuste, pensée pour les charges de travail IA. Contrairement à un simple appel d’API cloud, il faut héberger le modèle et tout son écosystème en interne. Cette intégration se fait directement dans le système d’information de l’entreprise.
Cela nécessite une infrastructure matérielle adaptée. Elle inclut des serveurs équipés de GPU ou TPU, des réseaux internes à haute bande passante et un stockage rapide. Ces ressources permettent d’héberger les jeux de données et les modèles, souvent volumineux.. Ces ressources assurent l’inférence du modèle en temps voulu, voire sa fine-tuning sur des données locales.
Plusieurs couches composent l’architecture d’un LLM d’entreprise sur site :
- Infrastructure matérielle et capacité de calcul : La base d’un LLM interne repose sur une infrastructure adaptée aux charges IA. Elle inclut des serveurs équipés de GPU ou TPU pour accélérer les calculs d’inférence et de fine-tuning. Elle comprend aussi des réseaux internes à haute bande passante. Ceux-ci garantissent des échanges rapides entre les différents services. Enfin, des systèmes de stockage performants sont nécessaires pour héberger des modèles volumineux et des jeux de données importants. Cette couche est essentielle pour assurer des temps de réponse maîtrisés.
- Préparation et gouvernance des données : un LLM interne dépend directement de la qualité des données qu’il exploite. Cela nécessite la mise en place de pipelines dédiés. Ils permettent d’ingérer, nettoyer et structurer les données internes. Ces données peuvent provenir de documents, d’emails, de logs ou de bases métiers.(documents, emails, logs, bases métiers). Des mécanismes de gouvernance doivent être intégrés dès cette étape. Ils incluent la classification des données, leur anonymisation, leur masquage et leur traçabilité. Ces pratiques permettent de respecter les exigences du Règlement général sur la protection des données. Elles garantissent aussi un usage sécurisé et contrôlé de l’information au sein de l’organisation.
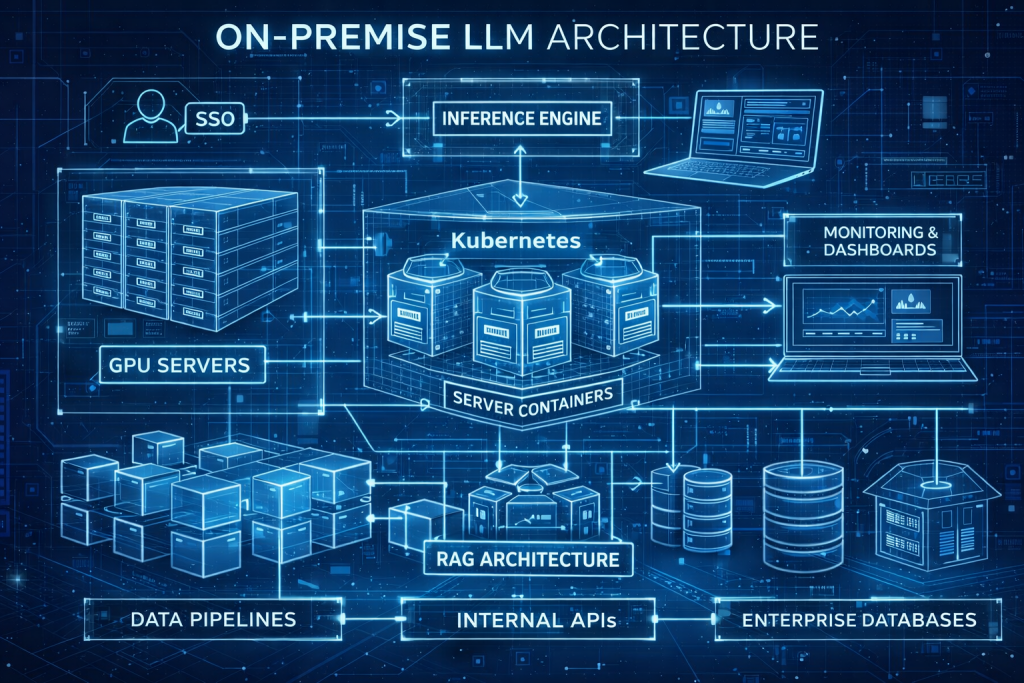
Intégration, supervision et évolutivité du système
Concevoir cette architecture nécessite de trouver un équilibre entre performance, coût et flexibilité. Par exemple, une banque pourrait choisir une approche hybride : garder on‑premise le noyau LLM traitant des données client confidentielles, tout en exploitant le cloud public pour des tâches d’entraînement intensives non sensibles. L’architecture doit alors être modulaire pour répartir intelligemment les charges. Ce qui se dessine, c’est souvent une infrastructure IA modulaire : un système principal dans le datacenter local (le “cerveau central”) épaulé au besoin par des composants périphériques ou cloud (“cerveaux d’appoint”) selon les cas d’usage. Cette modularité, via des conteneurs et microservices, permet aussi de faire évoluer chaque composant indépendamment : par exemple, améliorer le module d’inférence sans toucher aux connecteurs de données ou aux règles de sécurité.
En somme, l’architecture d’un LLM interne revient à bâtir sa propre « centrale d’IA » en entreprise, ajustée à ses besoins. Cela demande un investissement initial (matériel, mise en place DevOps/MLOps) plus lourd que d’appeler une API cloud, mais qui se rentabilise sur la durée dès lors que l’IA est intensément utilisée. Une fois en place, cette architecture interne offre stabilité des coûts (pas de facturation à la requête surprise), personnalisation poussée (le modèle parle le langage de l’entreprise) et intégration transparente aux processus métier. La réussite technique repose sur une bonne planification : anticiper les pics de charge, choisir des composants open-source performants et adopter une culture DevOps/IA pour faire évoluer l’ensemble en souplesse.
Sécurité et conformité : RGPD, AI Act et gouvernance de l’IA
Sécuriser un LLM interne ne se limite pas à installer un pare-feu autour du serveur hébergeant le modèle. Il s’agit d’imbriquer l’IA dans le cadre de sécurité existant de l’organisation, et d’y ajouter des contrôles spécifiques aux modèles de langage. L’avantage, c’est qu’en on‑premise, l’équipe sécurité peut appliquer ses propres règles à tous les niveaux : du chiffrement des données d’entraînement aux filtres sur les réponses générées.
Sécurité et protection des données dans un LLM interne
Sécuriser un LLM interne ne consiste pas simplement à ajouter une couche de protection réseau, mais à intégrer profondément l’intelligence artificielle dans l’écosystème de sécurité global de l’entreprise, en y ajoutant des mécanismes spécifiques aux modèles de langage. L’un des principaux avantages d’un déploiement on-premise est la maîtrise totale de l’environnement : toutes les opérations, de la préparation des données jusqu’à l’inférence en temps réel, sont exécutées à l’intérieur du périmètre sécurisé de l’organisation, sans exposition à des services externes.
Cela permet d’assurer une étanchéité stricte des données sensibles, qu’il s’agisse de données clients, de documents internes ou d’informations stratégiques, tout en facilitant la conformité avec des réglementations comme le Règlement général sur la protection des données. Dans ce cadre, les entreprises peuvent appliquer leurs propres politiques de chiffrement, de stockage et de localisation des données, garantissant que celles-ci restent hébergées sur des infrastructures maîtrisées, que ce soit dans un datacenter local au Maroc ou en Europe.
Cette approche réduit significativement les risques liés aux transferts transfrontaliers ou à l’exposition à des juridictions étrangères, tout en renforçant la confiance des parties prenantes. Par ailleurs, la mise en place de mécanismes de journalisation détaillée permet de tracer chaque interaction avec le modèle, incluant les requêtes, les réponses et les métadonnées associées, offrant ainsi une transparence complète et facilitant les audits internes et externes dans un contexte réglementaire de plus en plus exigeant.

Gouvernance, contrôle des usages et gestion des risques IA
Au-delà de la protection des données, la mise en œuvre d’un LLM interne permet de structurer une véritable gouvernance de l’IA, en intégrant des contrôles avancés sur les usages, les accès et les risques spécifiques liés aux modèles génératifs. Grâce à une intégration native avec les systèmes d’authentification de l’entreprise (SSO, annuaires internes), il devient possible d’appliquer le principe du moindre privilège, en limitant l’accès aux données en fonction du rôle de chaque utilisateur, évitant ainsi toute exposition non autorisée d’informations sensibles.
Des mécanismes de guardrails peuvent être configurés pour filtrer les sorties du modèle et empêcher la génération de contenus inappropriés ou confidentiels, complétés par des systèmes de supervision capables de détecter des comportements anormaux, comme des tentatives de prompt injection ou de contournement des règles du modèle. Cette approche permet également de répondre aux exigences croissantes en matière de conformité, notamment dans le cadre du futur AI Act, en intégrant dès la conception des pratiques de “governance by design” incluant la documentation complète du cycle de vie du modèle, le versioning, les évaluations de biais et les mécanismes de contrôle continu. Enfin, en maîtrisant entièrement son infrastructure IA, l’entreprise peut anticiper et mitiger les nouveaux risques liés à l’IA générative, tout en construisant un cadre de confiance durable, où performance technologique et exigences réglementaires avancent de concert.
Contraintes réseau : latence, bande passante et déploiement à l’edge
Choisir un LLM interne implique de relever des défis d’infrastructure réseau. En effet, passer d’un modèle hébergé sur le cloud (chez un fournisseur qui dispose de centres de données massifs et d’un backbone mondial) à un modèle hébergé sur site signifie que la performance et la portée dépendront de votre réseau d’entreprise. Trois contraintes majeures émergent : la latence, la bande passante et la résilience de la connectivité.
Latence et performance : l’avantage décisif du local et de l’edge
La latence est souvent le premier motif de basculement vers l’interne ou l’edge. Pour de nombreux cas d’usage, réduire le temps de réponse est critique. Un aller-retour vers un serveur cloud peut ajouter des centaines de millisecondes, voire plus d’une seconde si le réseau est saturé ou si le datacenter du fournisseur est éloigné géographiquement. Pour un chatbot interne répondant à des employés, quelques secondes de délai peuvent sembler acceptables. En revanche, pour des applications temps réel (industrie 4.0, santé, transport autonome), chaque milliseconde compte.
Par exemple, dans un véhicule autonome, le système IA doit interpréter les données de capteurs et agir quasiment instantanément : il est impensable d’envoyer ces données sur le cloud, attendre la réponse du LLM, puis freiner le véhicule – quelques centaines de ms de latence pourraient faire la différence entre éviter ou percuter un obstacle. Le edge computing s’impose alors : embarquer un modèle (certes plus petit) directement à bord de la voiture ou sur un serveur local proche, pour garantir des délais de l’ordre de 10–50 ms au lieu de 500 ms+ avec un aller-retour cloud.
De même, dans un contexte de maintenance industrielle en temps réel, un LLM déployé sur le réseau local d’une usine pourra analyser des alertes machines instantanément, alors qu’une solution cloud subirait la latence réseau et pourrait manquer à réagir à temps.
Bande passante et optimisation des flux de données
La bande passante est l’autre face de la médaille. Les LLM manipulent de gros volumes de données : documents ingérés, embeddings vecteurs, etc. Externaliser ces flux vers le cloud peut vite saturer une connexion internet ou engendrer des coûts élevés de sortie de données. En rapatriant le modèle en local, on garde les échanges dans le LAN de l’entreprise, souvent bien plus rapide et illimité en volume.
Cependant, cela suppose que le réseau interne soit à la hauteur : un modèle de 10 Go qu’il faut diffuser vers 10 sites distants de l’entreprise pour qu’ils l’exécutent, c’est potentiellement 100 Go de trafic à travers le WAN lors d’une mise à jour. Il faut donc planifier ce genre de distribution (peut-être via des CDN internes ou en profitant des heures creuses). Par ailleurs, traiter localement évite aussi de payer des frais de transit cloud (certains fournisseurs facturent la sortie de données).
En local, la donnée “circule moins” : on la traite là où elle est produite, ce qui allège le trafic global et améliore l’efficacité. On estime par exemple que transmettre un modèle de 6 Go sur une liaison 100 Mbps prendrait près de 8 minutes ; en déployant préalablement ce modèle sur chaque site localement, on évite d’avoir à faire ce transfert à chaque requête. C’est un vrai plus pour des environnements comme les navires en mer, les sites miniers reculés ou toute zone à connectivité contrainte : l’edge AI fonctionne même en cas de bande passante limitée ou de coupure.

Résilience réseau et continuité de service
Un LLM interne apporte un avantage clé en matière de continuité de service. Là où une solution cloud devient indisponible en cas de coupure de connexion, un modèle déployé localement continue de fonctionner sans interruption. Cette autonomie est essentielle dans des environnements critiques ou isolés, où la dépendance à Internet représente un risque opérationnel majeur. Des cas concrets illustrent cette réalité, notamment dans des infrastructures industrielles ou minières où la connectivité est limitée, voire inexistante. Dans ce type de contexte, les systèmes d’IA doivent impérativement être déployés en edge local afin de garantir leur disponibilité et leur efficacité.
En parallèle, garder l’IA au sein du réseau interne réduit significativement la surface d’attaque. Le modèle n’est pas exposé sur Internet et reste accessible uniquement via des réseaux sécurisés, comme un VPN ou un intranet d’entreprise. Cette approche renforce la cybersécurité globale et limite les risques liés aux accès non autorisés ou aux attaques externes.
Edge vs cloud : le choix n’est pas binaire.
La stratégie optimale consiste souvent à combiner les deux en fonction des besoins. Pour éclairer la décision, on peut se poser quelques questions clés :
- Quelle est la volumétrie de données et la capacité de calcul requise ? Si l’usage implique d’énormes volumes à traiter et des modèles géants, un cloud peut offrir la puissance évolutive à moindre coût. Si au contraire les données sont localisées et modérées en volume, un traitement local est envisageable.
- Quelle est la qualité du réseau disponible ? Une entreprise dotée d’une dorsale fibre 10 Gbps entre ses sites pourra centraliser un LLM au siège. Si certains sites n’ont qu’un accès limité (ex. agences éloignées, zones rurales), il faudra rapprocher le calcul, voire installer un serveur edge sur place.
- Le cas d’usage nécessite-t-il du temps réel ou une faible latence ? Un cas d’usage comme l’assistance aux médecins en chirurgie, ou la traduction instantanée dans une conférence, exigent un traitement local (edge) pour avoir des réponses en quelques millisecondes. À l’inverse, pour de l’analyse de reporting non-urgente, le cloud conviendra très bien même avec 2 secondes de latence.
- Quid de la résilience et de la confidentialité ? Si l’application doit absolument fonctionner en autarcie (ex : systèmes militaires sur le terrain, dispositifs médicaux), l’edge est indispensable. De même si les données sont hypersensibles et qu’on veut zéro échange extérieur (ex : données gouvernementales classifiées), l’on‑premise s’impose.
Architecture distribuée et optimisation des performances
Souvent, la solution consiste à avoir “un grand cerveau central et de petits cerveaux en périphérie”. Par exemple, une entreprise peut héberger son modèle principal dans un datacenter national pour consolider la puissance de calcul, tandis que des mini-LLM spécialisés opèrent sur les appareils edge pour filtrer ou pré-traiter les données localement. Ces derniers peuvent être des versions compressées du modèle principal (distillation) ou des modèles open-source plus petits adaptés à un CPU ou à un Jetson embarqué. Ainsi, seul l’essentiel transite sur le réseau vers le centre, réduisant la bande passante utilisée tout en garantissant une réponse locale rapide pour les tâches simples.
En somme, le déploiement d’un LLM interne oblige à penser l’architecture réseau de façon holistique. Il faut éventuellement investir dans de meilleures liaisons internes, segmenter le trafic IA pour lui garantir de la QoS, et rapprocher le calcul des utilisateurs finaux quand c’est nécessaire (edge computing). Le bénéfice, c’est une IA plus performante et fiable : on élimine les temps de trajet inutiles, on utilise de façon optimale les ressources locales, et on assure la continuité de service même en conditions dégradées.
Cette approche rejoint le mouvement plus large du Fog Computing, où le cloud et le edge coopèrent. Pour les entreprises marocaines ou françaises qui déploient des LLM internes, cela peut signifier par exemple de mettre en place un hub IA régional à Casablanca ou Paris desservant les antennes locales, tout en gardant des nœuds de calcul de secours sur site pour les tâches critiques. L’important est d’aligner la stratégie IA avec la réalité du terrain : là où se trouvent vos données et vos utilisateurs, doit se trouver votre intelligence artificielle.
Panorama des solutions LLM internes : outils et plateformes
Bonne nouvelle pour les DSI : on n’est plus en 2020 face à une page blanche pour déployer un LLM sur site. Un écosystème foisonnant d’outils “LLMops” et de solutions clé en main est apparu pour faciliter la vie des entreprises souhaitant un LLM interne. Du simple exécutable open-source aux suites intégrées des grands acteurs, il existe des options pour tous les besoins.
Ollama : la solution idéale pour démarrer
Ollama est un exemple emblématique de solution légère pour démarrer. Cet outil open-source propose un serveur local de LLM ultra-simple à installer (une commande shell suffit) et compatible avec de nombreux modèles open (LLaMA 2, GPT-J, etc.).
Ollama se distingue par sa facilité d’usage : il gère automatiquement le téléchargement et l’optimisation des modèles, supporte des versions quantifiées (exécutables sur CPU ou petites GPU), et offre une interface basique pour poser des questions en local. C’est l’idéal pour prototyper rapidement sur son PC ou démontrer en interne un POC d’assistant IA, le tout sans envoyer une requête en dehors.
De plus, Ollama fonctionne sur Windows, Mac, Linux, ce qui le rend flexible. Néanmoins, dès qu’on dépasse un usage individuel ou qu’on vise des performances élevées, ses limites apparaissent : peu de parallélisme et pas de mise à l’échelle sur plusieurs machines. En clair, Ollama est parfait pour le départ (labos R&D, petites équipes) mais pas pour la production à grande échelle.
vLLM : un moteur d’inférence haute performance
À l’autre bout du spectre, on trouve des moteurs optimisés comme vLLM. vLLM est un serveur d’inférence avancé, conçu pour tirer le maximum de throughput d’un modèle sur du matériel de centre de données. En exploitant des techniques d’allocation mémoire innovantes (PagedAttention) et du batching continu, vLLM parvient à servir un nombre élevé de requêtes en parallèle avec une latence réduite.
Des benchmarks ont montré qu’il peut délivrer 10 à 20 fois plus de requêtes par seconde qu’une solution naïve, tout en maintenant des réponses quasi instantanées même sous forte charge. En production, cela signifie qu’une instance vLLM sur un serveur équipé de GPUs A100/H100 pourra gérer les requêtes de centaines d’utilisateurs simultanés là où Ollama saturerait à quelques utilisateurs. L’envers de la médaille est la complexité : vLLM requiert de bien configurer son environnement GPU, éventuellement d’affiner des paramètres (taille de batch, etc.), et ne gère pas nativement le passage à plusieurs nœuds (pas de clustering multi-serveurs intégré).
Il est donc adapté pour un service centralisé sur un serveur puissant. De nombreuses entreprises choisissent ce genre de moteur pour déployer en interne un chatbot métier à l’échelle de toute l’organisation, car il combine efficacité et contrôle granulaire. Red Hat, par exemple, recommande vLLM pour les déploiements à forte charge, tandis qu’un outil comme Ollama resterait utile pour les développeurs en phase de développement individuel.
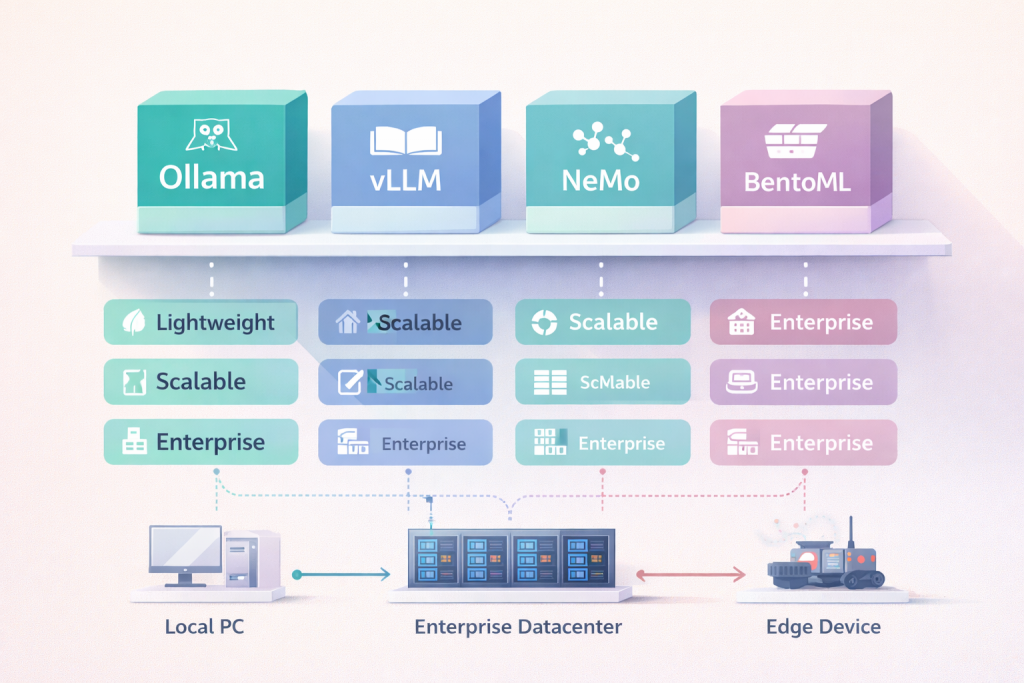
NVIDIA NeMo : une plateforme industrielle complète
NVIDIA NeMo représente une autre catégorie : celle des plateformes industrielles complètes. NeMo fournit un cadre modulaire incluant : des modèles pré-entraînés (les GPT maison de NVIDIA et partenaires), des outils de fine-tuning, des microservices déployables on‑premise (via NVIDIA AI Enterprise) pour servir les modèles, et même des fonctionnalités de guardrails et d’analyse de l’explicabilité. En choisissant NeMo, une entreprise s’appuie sur une solution supportée par NVIDIA (souvent optimisée pour tourner sur leurs stations DGX ou leurs GPUs en général).
L’avantage, c’est une intégration poussée – par exemple NeMo peut s’interfacer avec Triton Inference Server pour une mise en production scalable, et inclut des connecteurs vers des bases vectorielles, etc. C’est un choix pertinent pour industrialiser un LLM interne de A à Z : on peut fine-tuner un modèle propriétaire avec NeMo, le déployer en container sur son cloud privé et ajouter des garde-fous en quelques clics. En revanche, cela suppose un investissement financier (licences NVIDIA AI Enterprise) et une dépendance à un écosystème propriétaire – acceptable pour certains, rédhibitoire pour d’autres qui préfèrent du 100 % open-source.
Outils LLM interne
Aux côtés de ces trois-là, l’écosystème comporte pléthore d’autres outils LLM internes. Citons par exemple Hugging Face Text Generation Inference (TGI), un serveur open-source optimisé pour déployer les modèles de la hub HuggingFace en production (supporte le multi-GPU, le quantifié, etc.). Beaucoup d’organisations utilisent TGI couplé à des pipelines Transformers pour servir leurs modèles sur site. TensorRT-LLM est une librairie NVIDIA offrant des optimisations extrêmes (compilation bas niveau du modèle) pour des inférences ultra-rapides sur GPU – idéale si l’on vise le maximum de throughput sur du matériel NVIDIA. Des initiatives comme vLLM l’intègrent d’ailleurs parfois en backend pour gagner en perf. Pour les environnements contraints ou l’edge, on voit émerger des variantes spécialisées
Côté déploiement et orchestration, des solutions facilitatrices apparaissent aussi. On parle de plus en plus de “LLMOps”, à l’image du MLOps pour le machine learning classique. Par exemple, BentoML propose une plateforme open-source où l’on peut packager un modèle (qu’il soit Ollama, vLLM, TGI…) et le déployer en quelques commandes sur une infrastructure Kubernetes, avec monitoring et scaling automatique. De même, Ray Serve est utilisé par certains pour distribuer la charge d’un LLM sur plusieurs machines en parallèle. Ces outils comblent un besoin : opérer un LLM interne de manière fiable et automatiser son passage à l’échelle en cas de hausse d’utilisation.
Azure OpenAI
Enfin, les grands fournisseurs cloud eux-mêmes ont pris acte de la demande de solutions souveraines. On voit apparaître des offres type Azure OpenAI on-prem (Azure Arc), où Microsoft permet d’exécuter certains modèles GPT sur des appliances Azure locales, ou encore IBM watsonx qui met en avant un déploiement “où vous voulez” de ses modèles. Même OpenAI a annoncé en 2023 travailler sur une version “private” de ChatGPT pouvant tourner dans un environnement dédié pour de grands clients. Cela indique que d’ici 2026, la frontière entre cloud et on‑premise sera de plus en plus poreuse : les entreprises pourront acheter des modèles généraux mais les faire tourner chez elles, afin de combiner le meilleur des deux mondes (la puissance du modèle du leader, et la confidentialité locale).
Parallèlement, les grandes entreprises disposent de solutions plus complètes, souvent hybrides, leur permettant d’intégrer l’IA à grande échelle tout en respectant leurs contraintes de sécurité et de gouvernance. L’innovation continue dans ce domaine accélère encore cette adoption, avec l’émergence constante de nouveaux outils plus légers, plus performants ou plus spécialisés.
Dans ce contexte, l’enjeu principal devient stratégique : choisir la bonne combinaison technologique selon ses besoins, entre simplicité, performance ou solutions enterprise. Internaliser un LLM ne relève plus seulement d’un choix technique, mais d’un positionnement fort permettant à l’entreprise de gagner en autonomie, en compétitivité et en différenciation sur son marché.
Conclusion : tirer parti du LLM interne en alliant stratégie et responsabilité

Les LLM internes s’imposent comme un levier clé d’une transformation numérique responsable à l’horizon 2026. En maîtrisant leur architecture, les entreprises intègrent l’IA au cœur de leurs systèmes sans dépendance excessive à des fournisseurs externes, tout en l’adaptant précisément à leurs enjeux métier. Cette approche renforce la sécurité et la conformité, transformant les contraintes réglementaires comme le RGPD ou l’AI Act en avantages concurrentiels. Les solutions d’IA inspirent ainsi davantage confiance, aussi bien auprès des collaborateurs que des clients et des régulateurs. Par ailleurs, une implantation maîtrisée des infrastructures permet d’atteindre des performances élevées – faible latence, forte disponibilité – tout en réduisant les coûts cachés du cloud et les risques opérationnels.
Un LLM interne réussi dépasse la simple dimension technologique. Il constitue un socle de souveraineté numérique, d’agilité stratégique et de gouvernance renforcée. Les entreprises gagnent en indépendance face aux évolutions des fournisseurs cloud et conservent un contrôle total sur leurs données et leurs usages. Certes, cette démarche implique des investissements initiaux en infrastructure et en compétences, ainsi qu’un accompagnement au changement. Mais ces efforts sont rapidement compensés par des bénéfices durables : innovation maîtrisée, conformité sécurisée et compétitivité renforcée.
À l’inverse, les organisations qui tardent à s’engager risquent de subir la hausse des coûts et le durcissement des régulations sans tirer pleinement parti de l’IA. La trajectoire est donc claire : adopter les LLM internes de manière proactive. Réussir cette transition, c’est aligner technologie, gouvernance et stratégie métier pour faire de l’IA un véritable moteur de performance et de confiance.
Prêts à franchir le pas ? La révolution des LLM internes ne fait que commencer – restez à l’écoute des avancées et n’hésitez pas à vous faire accompagner pour en tirer le meilleur. 🚀
Contactez-nous pour plus d’information.
FAQ LLM interne
Pourquoi déployer un LLM interne en 2026 ?
Un LLM interne permet aux entreprises de garder le contrôle total sur leurs données sensibles tout en respectant le RGPD et les exigences du futur AI Act. En hébergeant le modèle sur leurs propres serveurs, les organisations évitent les transferts de données vers des tiers et réduisent les risques juridiques, sécuritaires et réputationnels. Cette approche renforce la souveraineté numérique, limite le shadow AI et facilite les audits de conformité.
Quelle architecture technique pour un LLM interne performant ?
Une architecture de LLM interne repose sur des serveurs équipés de GPU, un stockage rapide et un réseau interne à haute bande passante. Elle inclut des pipelines de préparation des données, un service d’inférence conteneurisé, des API d’intégration métier et des outils MLOps de supervision. Cette structure modulaire permet d’optimiser la performance, d’assurer la scalabilité et d’intégrer le modèle aux systèmes existants sans dépendance externe.
Comment assurer la conformité RGPD et AI Act ?
Un LLM interne facilite la conformité RGPD et AI Act en maintenant les données personnelles dans le périmètre de l’entreprise. La journalisation des requêtes, la gestion fine des accès et la documentation du cycle de vie du modèle assurent traçabilité et auditabilité. Cette gouvernance intégrée dès la conception permet de répondre aux obligations réglementaires, de limiter les risques d’amende et de démontrer une utilisation responsable de l’intelligence artificielle.
Quels risques de sécurité spécifiques aux LLM ?
Un LLM interne doit se protéger contre des menaces comme le prompt injection, le model jailbreaking ou la divulgation involontaire d’informations sensibles. La mise en place de garde-fous, de filtres de contenu et de contrôles d’accès stricts réduit ces risques. La surveillance continue des réponses générées et l’intégration aux politiques de sécurité existantes renforcent la résilience globale du système d’intelligence artificielle.
Pourquoi la latence et le réseau influencent-ils le choix ?
Le choix d’un LLM interne dépend fortement des contraintes réseau comme la latence, la bande passante et la résilience. Un déploiement local ou en edge réduit les temps de réponse critiques pour des usages temps réel et limite les échanges de données vers le cloud. Cette approche améliore la continuité de service, optimise les performances et protège les données dans des environnements à connectivité limitée.
Quels outils déployer un LLM interne efficacement ?
Le déploiement d’un LLM interne peut s’appuyer sur plusieurs outils selon les besoins. Ollama est adapté aux prototypes simples et rapides à mettre en place. Pour des performances élevées et une meilleure gestion de la charge, vLLM constitue une solution efficace. Enfin, NVIDIA NeMo permet une industrialisation complète, avec des fonctionnalités avancées pour le déploiement et la gouvernance. Ces solutions permettent de gérer l’inférence, l’optimisation GPU et la mise à l’échelle. Le choix dépend des besoins en performance, en simplicité d’usage et en niveau de support enterprise recherché.


