

IDC estime que les dépenses mondiales en services de cloud public atteindront 805 milliards de dollars en 2024 et devraient doubler d’ici 2028
Le point de départ est clair : le cloud public est devenu l’option par défaut pour l’IA d’entreprise parce qu’il concentre l’offre GPU, les services managés, les outils d’orchestration et une vitesse d’expérimentation difficile à reproduire en interne. IDC estime que les dépenses mondiales en services de cloud public atteindront 805 milliards de dollars en 2024 et devraient doubler d’ici 2028, pendant que les dépenses mondiales en IA doivent dépasser 632 milliards de dollars à l’horizon 2028. Dans le même temps, l’adoption organisationnelle de l’IA continue de monter : le Stanford AI Index 2026 indique que 88 % des organisations interrogées utilisent déjà l’IA, et que 70 % emploient la GenAI dans au moins une fonction métier.
Mais « cloud par défaut » ne veut pas dire « cloud universel ». Uptime Institute relève qu’en 2025, 45 % des workloads IT résident encore dans des installations d’entreprise, ce qui confirme que l’on-premise reste une couche structurelle, pas un reliquat historique. Deloitte observe en parallèle que la plupart des organisations ne sont pas encore prêtes à industrialiser la GenAI : trois sur quatre signalent des défis majeurs de gestion du cycle de vie des données et six sur dix disent ne pas disposer de la bonne fondation data pour les cas d’usage GenAI.
La question stratégique n’est donc plus « cloud ou pas cloud ? » mais plutôt : quelles charges IA doivent rester sous contrôle direct de l’entreprise, pour quelles raisons, et avec quelle architecture cible ? En 2026, cette question se lie de plus en plus à la souveraineté numérique, à la cybersécurité, à la résilience opérationnelle, au coût de l’inférence continue et, dans les pays africains, à la disponibilité même d’une infrastructure hyperscale proche et conforme.
Le cloud est la norme, mais pas la réponse universelle
Si le cloud a gagné, c’est parce qu’il supprime l’essentiel du frottement initial : GPU à la demande, services d’IA prêts à l’emploi, environnements MLOps/GenAIOps standardisés, montée en charge quasi instantanée et portée mondiale. Les offres enterprise de NVIDIA, Red Hat, Google Cloud, Azure ou AWS sont précisément conçues pour raccourcir le passage du prototype à la production. IDC note d’ailleurs que les hyperscalers et fournisseurs de services dominent toujours la dépense infrastructure IA : au quatrième trimestre 2025, les États-Unis représentaient 77 % de la dépense mondiale d’infrastructure IA selon IDC.
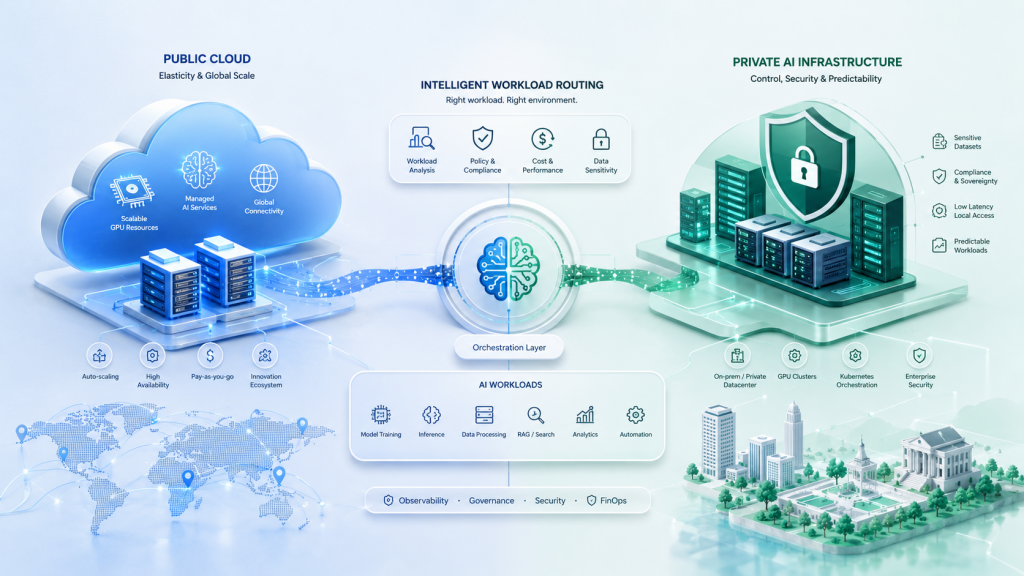
Cependant, les organisations qui refusent délibérément le cloud pour certains projets IA le font rarement par conservatisme technique. Les motifs réels sont plus structurels : protection de données sensibles, exposition du patrimoine informationnel, contrainte réglementaire sur les transferts, exigence de contrôle sur la chaîne logicielle, dépendance excessive à un fournisseur, prévisibilité budgétaire sur l’inférence continue, et besoin d’exécuter l’IA au plus près du terrain. Les fiches techniques de VMware Private AI Foundation with NVIDIA, HPE Private Cloud AI et AWS Wavelength montrent bien que les enjeux explicitement adressés sont la confidentialité, le coût, les performances, la conformité, la résilience et la proximité des données.
Autrement dit, le basculement vers l’IA privée n’est pas un rejet idéologique du cloud ; c’est un arbitrage de portefeuille. Les workloads exploratoires, fortement variables ou globalement distribués restent souvent mieux servis par le cloud public. En revanche, les cas d’usage à données hautement sensibles, trafic stable, latence contraignante ou criticité opérationnelle forte deviennent d’excellents candidats pour une IA locale, souveraine ou hybride. Cette lecture est cohérente avec l’état du marché : Lenovo, en s’appuyant sur une étude IDC commanditée pour son CIO Playbook 2026, affirme que 84 % des organisations s’attendent à faire tourner l’IA à la fois en on-premise ou à l’edge et dans le cloud. Même en tenant compte du biais fournisseur, le message rejoint les constats d’Uptime : l’avenir n’est pas tout-cloud, mais hybride avec une forte couche locale.
Souveraineté des données et pression réglementaire

Au Maroc, la base juridique est déjà suffisamment forte pour orienter l’architecture. La loi 09-08 encadre la protection des données personnelles ; la CNDP rappelle que le transfert de données personnelles à l’étranger n’est possible que dans des cas précis, notamment vers des pays figurant sur une liste établie par la CNDP ou sous conditions particulières prévues par la loi. La CNDP rappelle aussi qu’une autorisation préalable est exigée pour les traitements portant sur des données sensibles, y compris les données de santé et les données génétiques. Pour des projets IA manipulant dossiers patients, données KYC, scoring, voix, biométrie, réclamations ou traces comportementales, cette réalité pousse naturellement vers des architectures d’hébergement local, d’IA privée ou d’IA on-premise.
À cela s’ajoute le versant cybersécurité et infrastructures critiques. Le référentiel marocain ne s’arrête pas à la privacy : la loi 05-20 sur la cybersécurité impose des exigences accrues aux systèmes d’information sensibles et aux infrastructures d’importance vitale. Le National Cyber Security Index, en s’appuyant sur les textes de la DGSSI, indique qu’en application de cette loi, le décret 2-24-921 encadre désormais l’usage des fournisseurs de services cloud pour les entités et infrastructures critiques gérant des systèmes ou données sensibles, via un cadre de qualification et de sélection des prestataires. Pour les secteurs banque, énergie, télécoms, administration, santé ou opérateurs essentiels, l’architecture IA n’est donc plus une simple décision d’ingénierie ; c’est aussi une question de conformité et d’homologation.
À l’échelle africaine, la trajectoire va dans le même sens. Le cadre de politique de données de l’Union africaine définit explicitement la souveraineté des données comme l’idée que les données générées dans ou transitant par l’infrastructure Internet nationale doivent être protégées et contrôlées par l’État, tout en soulignant que la localisation des données doit être évaluée selon un raisonnement coût-bénéfice. La stratégie continentale IA de l’UA insiste en outre sur deux points très concrets : de nombreux pays africains manquent encore de ressources de calcul puissantes avec GPU avancés, et l’insuffisance de bande passante ainsi que les règles de souveraineté rendent difficile l’usage de ressources de calcul extérieures pour expérimenter des solutions IA.
En Europe, le mouvement est différent mais convergent dans ses effets. Le RGPD impose des garde-fous sur les transferts vers des pays tiers, avec décisions d’adéquation, clauses contractuelles types et règles d’entreprise contraignantes. Les institutions financières européennes doivent en plus gérer les lignes directrices EBA sur l’outsourcing et, depuis janvier 2025, le règlement DORA sur la résilience opérationnelle numérique. En parallèle, l’AI Act européen introduit une couche supplémentaire de gouvernance sur les systèmes IA. Le résultat pratique est le même : même quand le cloud reste autorisé, les secteurs régulés doivent documenter le risque fournisseur, l’auditabilité, la continuité et les transferts. Dans ce contexte, l’IA on-premise redevient un levier de simplification réglementaire.
Le signal le plus important, au fond, n’est pas seulement juridique. Le Stanford AI Index 2026 souligne que la souveraineté de l’IA devient une caractéristique structurante des politiques nationales, avec des investissements publics croissants dans les capacités de calcul et les écosystèmes domestiques. C’est exactement le type de dynamique qui favorise les déploiements d’IA souveraine, d’IA locale et d’infrastructure IA en datacenter national plutôt que l’externalisation systématique chez les hyperscalers.
Réseau, latence et edge
McKinsey confirme que la demande africaine de capacité datacenter pourrait passer d’environ 0,4 GW à 1,5–2,2 GW d’ici 2030, avec 10 à 20 milliards de dollars d’investissement nécessaires.
Une partie décisive du débat sort du registre réglementaire pour entrer dans le physique. L’IA cloud fonctionne très bien tant que la latence, la bande passante et la disponibilité réseau restent compatibles avec le métier. Dès qu’une application doit inférer en temps réel, en boucle fermée, sur site distant ou en environnement industriel, le cloud devient moins une solution qu’un détour. Le livre blanc edge-native de la CNCF résume les bénéfices attendus du calcul à la périphérie : réduction de latence, maîtrise de la bande passante, meilleure confidentialité et continuité d’activité quand les réseaux sont peu fiables. AWS a créé Wavelength précisément pour répondre à ces contraintes, en parlant de latences à un chiffre en millisecondes pour certains cas 5G.
Pour le Maroc, l’indicateur le plus utile n’est pas un ranking marketing de débit mais la qualité de trajet réseau observable. Cloudflare Radar estimait, au moment de la consultation, un temps de trajet aller-retour moyen de 82 ms pour le Maroc sous charge moyenne. Ce n’est pas catastrophique pour des usages bureautiques ou des batchs analytiques, mais cela devient vite pénalisant pour de la vision industrielle, du voice AI temps réel, du contrôle qualité ligne par ligne, du pilotage d’équipement, de l’assistance en centre d’appel temps réel ou des systèmes transactionnels à faible tolérance au délai.
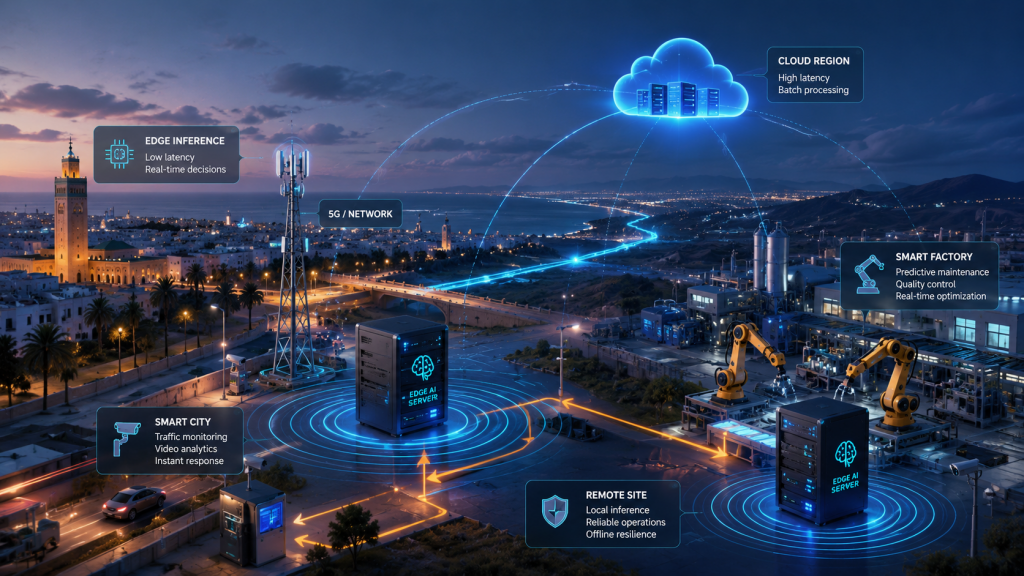
Le problème est accentué par la géographie des régions hyperscale. AWS dispose d’une région africaine à Cape Town et a ouvert une Wavelength Zone à Casablanca en 2025, qualifiée de première Wavelength Zone en Afrique du Nord. Google Cloud a ouvert sa région de Johannesburg en 2024. Azure liste, pour l’Afrique, les régions South Africa North et South Africa West. Autrement dit, l’Afrique progresse, mais la densité d’implantation reste très inférieure à l’Europe ou à l’Amérique du Nord, et le Maroc ne dispose pas, à la date de cette recherche, d’une région complète AWS/Azure/GCP équivalente aux grands clusters hyperscale ; il dispose en revanche d’une présence edge AWS via Orange.
La stratégie continentale IA de l’UA donne le contexte macro qui explique ce décalage. Elle indique que l’Afrique manque à la fois de compute puissant, de bande passante adéquate et de datacenters fiables ; elle ajoute que l’Afrique ne représente qu’environ 1,8 % des grands datacenters recensés en 2023 et qu’environ 10 % seulement de la demande de datacenter du continent est aujourd’hui servie. McKinsey confirme que la demande africaine de capacité datacenter pourrait passer d’environ 0,4 GW à 1,5–2,2 GW d’ici 2030, avec 10 à 20 milliards de dollars d’investissement nécessaires. Dans un tel contexte, les architectures IA locales ne sont pas seulement une préférence de souveraineté : elles deviennent un outil pragmatique de réduction de dépendance à des régions lointaines.
Architectures on-premise en 2026
Le paysage 2026 n’a plus grand-chose à voir avec l’on-premise artisanal d’il y a cinq ans. Les fournisseurs convergent vers des AI factories et des plateformes privées prévalidées : serveurs GPU, réseau haut débit, stockage haute performance, orchestration Kubernetes, couches logicielles d’inférence et de MLOps, et catalogues de modèles. NVIDIA décrit son Enterprise AI Factory comme un design full-stack validé pour construire et déployer une AI factory sur site, avec calcul accéléré, réseau, software stack NVIDIA AI Enterprise et écosystème partenaires. Dell, HPE, Cisco, Lenovo et Broadcom/VMware s’alignent tous sur cette logique.
Sur le plan logiciel, Red Hat OpenShift AI illustre bien la normalisation en cours : la plateforme combine MLOps, GenAIOps et AgentOps, avec des outils ouverts comme PyTorch, Kubeflow, MLflow et vLLM. En pratique, cela permet d’intégrer l’IA dans les cycles habituels de plateforme d’entreprise : CI/CD, gestion des modèles, observabilité, gouvernance, tenancy, sécurité des conteneurs et exploitation de clusters GPU. Pour les DSI déjà organisées autour de Kubernetes ou d’OpenShift, c’est souvent l’option la plus cohérente pour industrialiser une IA privée sans repartir de zéro.

Les offres « appliance » ou « private AI in a box » répondent à un autre profil : celui des organisations qui veulent limiter les risques d’intégration. HPE Private Cloud AI, co-conçu avec NVIDIA, met en avant un déploiement rapide d’une plateforme privée focalisée sur l’inférence, le RAG et le fine-tuning avec contrôle privé des données. VMware Private AI Foundation with NVIDIA vise les entreprises déjà fortement virtualisées sous VMware Cloud Foundation, pour exécuter RAG, fine-tuning et inférence dans leurs datacenters en répondant à des préoccupations explicites de confidentialité, de coût, de performance et de conformité. Dell AI Factory with NVIDIA avance une architecture modulaire avec points d’entrée distincts pour petite inférence, fine-tuning, entraînement et montée progressive en production.
Cisco, de son côté, pousse une approche modulaire et sécurisée. Sa fiche AI PODs indique un stack prévalidé couvrant tout le cycle de vie IA, du fine-tuning à l’inférence à haut débit, avec réduction possible du temps de déploiement jusqu’à 50 %, croissance de 32 à plus de 128 GPU par cluster et latence sub-millisecond pour des tâches IA exigeantes. Ce type d’offre est particulièrement pertinent pour les organisations qui veulent standardiser l’infrastructure IA comme une extension de leur réseau et de leur datacenter existants.
Le choix technologique réel se structure donc autour de quatre briques : compute GPU, stockage pour pipelines RAG et données, orchestration de workloads, couche logicielle d’inférence/serving. Dans la pratique, l’architecture gagnante au Maroc et en Afrique sera souvent hybride par conception : inférence locale, RAG local, données sensibles conservées sur site, et extension cloud réservée à l’entraînement ponctuel, au burst capacity ou aux modèles non critiques. Les documents fournisseurs eux-mêmes reconnaissent ce modèle “run anywhere” et la coexistence on-prem, edge et cloud.
Quels modèles fonctionnent localement
La réponse courte est la suivante : oui, beaucoup de modèles sont localement exploitables, mais pas tous au même niveau de qualité, de coût ni de gouvernance. Les meilleurs candidats pour l’IA on-premise en 2026 sont les modèles ouverts ou open-weight de taille petite à moyenne, puis les architectures enrichies par RAG plutôt que les très grands modèles servis bruts. Mistral Small 3.1 se positionne explicitement dans la catégorie des “small models” avec 128k de contexte ; Gemma 3 insiste sur sa capacité à être déployée sur laptops, desktops ou infrastructure privée ; Phi-4 est un modèle dense de 14 milliards de paramètres orienté raisonnement.
Meta met en avant Llama 4 Scout comme un modèle qui tient sur un seul GPU NVIDIA H100 avec quantification Int4, tandis que Llama 4 Maverick peut tenir sur un seul hôte H100. Cela signifie qu’un nombre croissant de cas d’usage enterprise ne requiert plus nécessairement un cluster massif pour offrir des performances crédibles, surtout en inférence et en assistant spécialisé. La contrepartie reste juridique et opérationnelle : Llama est largement disponible, mais sous licence Meta et non sous une licence open source classique au sens strict.
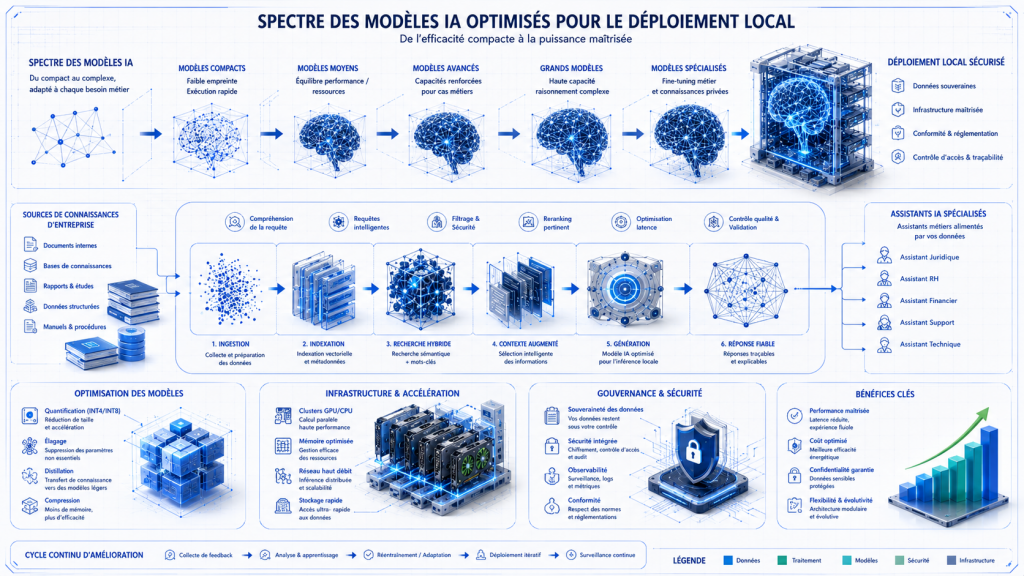
DeepSeek-R1 illustre bien la nuance entre « modèle open » et « modèle localement réaliste ». Le modèle principal affiche 671 milliards de paramètres au total, avec 37 milliards activés, ce qui reste lourd pour la plupart des SI d’entreprise ; en revanche, DeepSeek a publié des versions distillées de 1.5B, 7B, 8B, 14B, 32B et 70B. En pratique, ce sont ces distillations qui rendent viable une stratégie d’IA locale pour assistants métiers, Q&A documentaire, copilotes internes ou agents spécialisés.
La clé, en 2026, n’est pas seulement le choix du modèle mais l’optimisation de son exécution. La quantification réduit l’empreinte mémoire et le coût de calcul en abaissant la précision des poids et/ou activations. NVIDIA souligne que TensorRT et TensorRT-LLM supportent plusieurs schémas de quantification — INT8, FP8, FP4/NVFP4 — pour réduire le coût et accélérer l’inférence. Hugging Face rappelle que les techniques 8-bit et 4-bit permettent de charger des modèles plus gros dans une mémoire limitée et d’accélérer l’exécution. vLLM ajoute une couche importante : toutes les méthodes de quantification ne sont pas disponibles sur tous les matériels, donc le choix du backend et du GPU reste structurant.
Pour un DSI ou un CTO, la bonne règle n’est donc pas « choisir le plus gros LLM possible », mais plutôt : petit ou moyen modèle + données internes + RAG + garde-fous + serving optimisé. Cette combinaison explique pourquoi les plateformes privées 2026 mettent l’accent sur l’inférence locale, le fine-tuning ciblé et le RAG, beaucoup plus que sur l’entraînement complet de très grands modèles.
Arbitrages réels sur le coût, la sécurité, l’énergie et les compétences
Le premier mythe à corriger est que l’IA on-premise serait systématiquement plus économique. Ce n’est vrai ni dans tous les cas ni sur tous les horizons. L’investissement initial est lourd : serveurs GPU, réseau, stockage, refroidissement, électricité, licences, exploitation. L’IEA projette que la consommation électrique des datacenters mondiaux pourrait atteindre environ 945 TWh en 2030, soit plus du double du niveau actuel, avec l’IA comme moteur majeur de croissance. NVIDIA indique qu’un H100 peut monter jusqu’à 700 W de TDP, et le H200 NVL peut lui aussi aller jusqu’à 700 W selon configuration. Une stratégie IA on-premise implique donc un projet d’énergie autant qu’un projet logiciel.
Le second mythe est que toute entreprise peut facilement absorber ces charges. Uptime montre que la plupart des datacenters restent encore sous 30 kW par rack, que les densités extrêmes sont rares et que les difficultés de staffing persistent, près des deux tiers des opérateurs signalant des problèmes de rétention ou de recrutement. Cela signifie que l’IA on-premise à forte densité n’est pas seulement une question d’achat de GPU ; c’est une question de compétences datacenter, d’exploitation, de refroidissement, de sécurité, d’observabilité et de gouvernance plateforme.

En revanche, il y a deux cas où l’économie de l’on-premise devient souvent convaincante. Premièrement, lorsque l’inférence est continue, prévisible et volumineuse : assistants internes, classification documentaire, recherche augmentée, contrôle qualité industriel, génération de compte-rendus, détection de fraude. Deuxièmement, lorsque le coût indirect du cloud — transfert de données, localisation, latence, audit, redondance réglementaire — devient supérieur au coût d’une capacité locale amortie. C’est une inférence stratégique fondée sur la combinaison des données de marché IDC, des contraintes réglementaires et des architectures fournisseurs plutôt qu’un chiffre universel de TCO.
Le tableau ci-dessous synthétise les arbitrages principaux. Il s’agit d’une grille d’aide à la décision, pas d’un benchmark universel ; les appréciations varient selon le volume d’inférence, la criticité réglementaire, la proximité de régions cloud, le prix local de l’électricité et le niveau de maturité MLOps de l’organisation. Cette synthèse s’appuie sur Uptime, IDC, l’IEA et les documentations techniques NVIDIA, HPE, Cisco, Dell et Broadcom/VMware.
| Critère | IA on-premise | IA hybride | IA cloud public |
|---|---|---|---|
| Confidentialité des données | Très forte si gouvernance interne mature | Forte sur les données critiques | Variable selon contrat, région et transferts |
| Conformité réglementaire | Souvent la plus simple pour données sensibles/localisées | Bonne si segmentation claire | Plus complexe en secteurs régulés |
| Latence et temps réel | Excellente au plus près des usages | Très bonne si edge + cloud maîtrisés | Bonne à moyenne selon région |
| Scalabilité immédiate | Limitée au stock de capacité installé | Bonne si bursting cloud possible | Excellente |
| Coût initial | Élevé | Élevé mais plus flexible | Faible à l’entrée |
| Coût récurrent à forte charge | Potentiellement avantageux | Souvent optimal si bon découpage | Peut devenir élevé |
| Maintenance | Lourde | Moyenne à lourde | Faible côté client |
| Consommation énergétique locale | Élevée | Élevée mais partagée | Externalisée |
| Compétences requises | Très élevées | Élevées | Moyennes à élevées |
| Risque de lock-in | Matériel et stack possibles | Réparti | Souvent élevé côté services managés |
Maroc et Afrique, cas d’usage et cadre de décision
Dans le contexte marocain et africain, les cas d’usage les plus favorables à l’IA on-premise sont ceux où les contraintes régionales transforment un « nice to have » en nécessité structurelle. Le premier bloc, évident, est la banque et l’assurance : lutte contre la fraude, scoring, anti-blanchiment, assistants conseillers, recherche dans les dossiers clients, analyse de contrats et de réclamations. Ces usages croisent données sensibles, exigences de continuité, supervision cyber et parfois faible appétit pour l’externalisation. Le cloud n’y disparaît pas, mais l’inférence locale ou privée réduit l’exposition réglementaire. AWS cible d’ailleurs explicitement finance, secteur public, télécom et santé pour Wavelength au Maroc et au Sénégal, et DORA/EBA montrent combien la dépendance aux tiers technologiques est désormais surveillée dans les services financiers.
Le deuxième bloc est le secteur public, les infrastructures critiques et les environnements souverains. Reuters rapporte que le Maroc vise un gain de 100 milliards de dirhams de PIB lié à l’IA d’ici 2030, avec un accent explicite sur les datacenters souverains, la fibre, le cloud et la montée en compétences ; le gouvernement prépare également une législation sur l’IA. Dans ce contexte, les architectures d’IA locale pour administration, sécurité, justice, fiscalité, relation citoyen ou défense s’inscrivent logiquement dans une stratégie de souveraineté nationale plutôt que dans une simple optimisation IT.
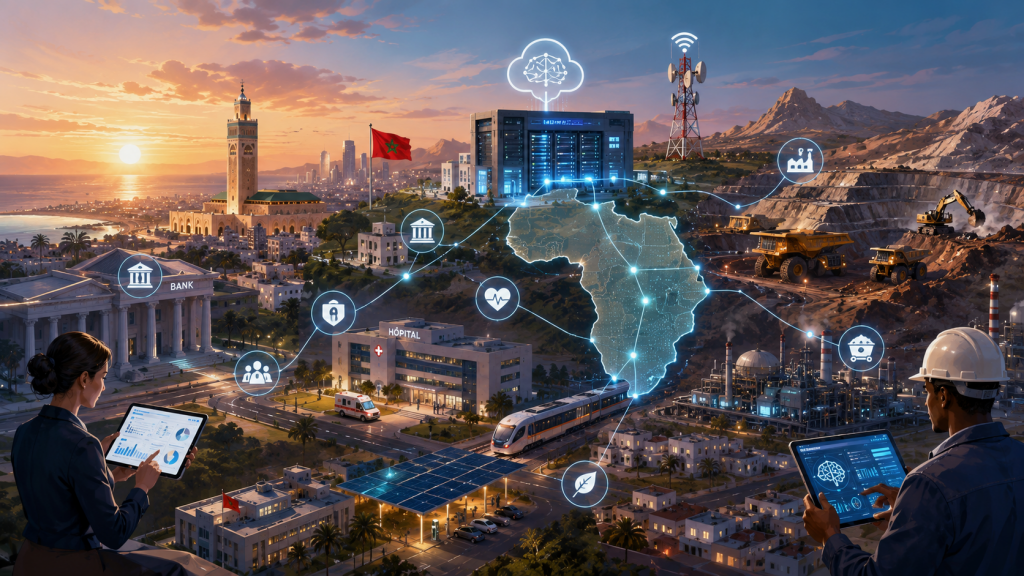
Le troisième bloc est la santé. Au Maroc, les données de santé sont explicitement des données sensibles au sens de la CNDP, avec régime d’autorisation ou de déclaration selon les cas, ce qui rend l’hébergement local particulièrement attractif pour transcription médicale, recherche documentaire clinique, aide au codage, résumé de consultation, imagerie et gouvernance des dossiers. Le Stanford AI Index 2026 note en outre une adoption très rapide d’outils de génération automatisée de notes cliniques, avec des gains déclarés de temps et de burnout dans certains systèmes hospitaliers ; mais le rapport souligne aussi que beaucoup d’études cliniques IA reposent encore sur des données trop éloignées du réel, ce qui plaide pour des déploiements ancrés dans les données locales et la validation locale.
Le quatrième bloc est l’industrie, l’énergie, les mines et les télécoms. Les cas d’usage y sont structurellement edge : vision industrielle, détection d’anomalies, maintenance prédictive, surveillance de sites, sécurité, optimisation énergétique, analyse vidéo, copilotes terrain, agents offline ou déconnectés. BMW montre ce que donne une industrialisation sérieuse : DGX pour l’entraînement et le déploiement, génération massive de données synthétiques, réduction de deux tiers du temps de mise en œuvre d’automatisations QA par les équipes métier et capacité à exécuter de la détection temps réel “en millisecondes”. Pour des sites éloignés, faiblement connectés ou très sensibles, cette logique locale est encore plus pertinente en Afrique.
Cadre de décision pour DSI, CTO et RSSI
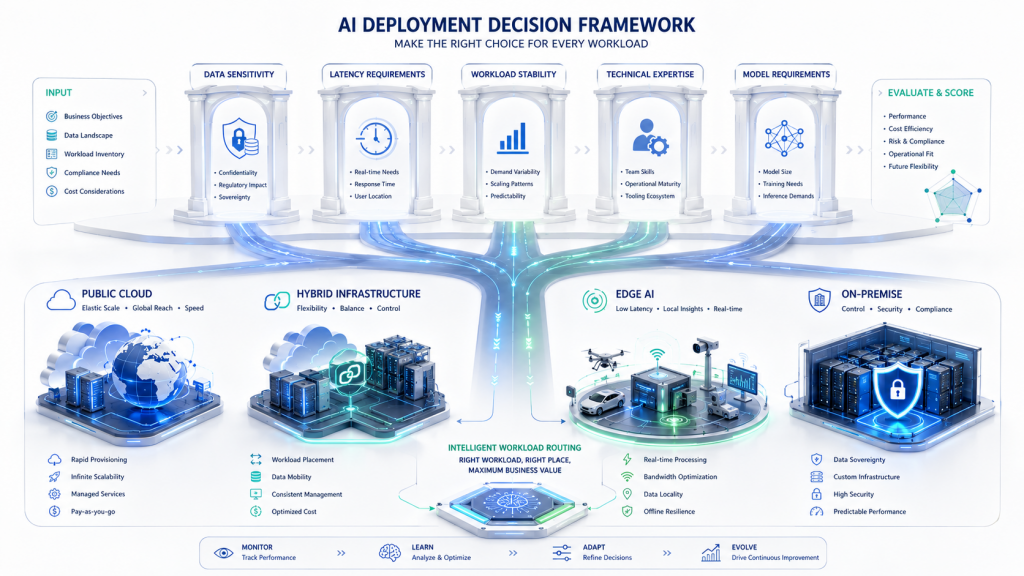
La bonne décision ne consiste pas à choisir une architecture unique pour toute l’entreprise. Elle consiste à segmenter les workloads IA selon cinq questions simples :
- Les données peuvent-elles juridiquement et contractuellement sortir du pays, du groupe ou du site ?
- Le cas d’usage tolère-t-il une latence de réseau non déterministe ?
- La charge d’inférence sera-t-elle stable et continue, ou seulement ponctuelle ?
- L’organisation possède-t-elle les compétences datacenter, GPU, sécurité, MLOps et SRE nécessaires ?
- Le besoin porte-t-il sur un modèle généraliste gigantesque, ou sur un modèle spécialisé appuyé par RAG et données locales ?
Ces critères dérivent directement des cadres CNDP/DGSSI, des recommandations africaines de souveraineté des données, des contraintes de réseau/edge et des options d’architecture private AI disponibles en 2026.
On peut en déduire une matrice de décision concise :
| Situation dominante | Architecture la plus cohérente |
|---|---|
| Données très sensibles, latence critique, charge stable | On-premise / IA privée |
| Données sensibles mais besoin de burst et de polyvalence | Hybride |
| Expérimentation rapide, charge variable, peu de contraintes réglementaires | Cloud public |
| Sites éloignés, opérations offline, vidéo/IoT temps réel | Edge AI + noyau on-premise |
| Banque, santé, secteur public, infrastructures critiques | Priorité au local ou au privé, cloud en extension ciblée |
Cette matrice est une synthèse analytique fondée sur les sources réglementaires, les contraintes d’infrastructure africaines, et les patterns techniques documentés par les grandes plateformes enterprise IA consultées.
Ce qu’il faut retenir
En 2026, l’IA on-premise n’est plus un marché de niche pour acteurs ultra-régulés ; c’est une option stratégique rationnelle dès lors que la donnée est sensible, que l’inférence est locale, que le coût du cloud devient récurrent et massif, ou que la géographie réseau rend le cloud trop éloigné. Pour le Maroc et une large partie de l’Afrique, l’argument prend encore plus de poids : souveraineté numérique, règles de transfert, infrastructures critiques, coûts de connectivité, disponibilité inégale des régions hyperscale, et volonté politique croissante de bâtir des capacités nationales convergent tous dans le même sens. Le choix d’infrastructure IA devient de moins en moins un simple arbitrage technique, et de plus en plus une décision de résilience, de gouvernance et de positionnement compétitif.

Questions ouvertes et limites
Cette recherche permet de conclure solidement sur les tendances, les cadres réglementaires et les patterns d’architecture, mais trois zones restent variables d’un projet à l’autre : le TCO exact selon prix local de l’électricité et taux d’utilisation GPU, la maturité réelle des datacenters locaux par pays africain hors grands marchés, et la vitesse de déploiement de nouvelles régions cloud ou cadres IA nationaux entre 2026 et 2027. Ces points devront être validés au cas par cas avant toute décision d’investissement.
FAQ – Pourquoi l’IA on-premise redevient une décision stratégique en 2026
Pourquoi choisir une architecture IA on-premise en 2026 ?
L’IA on-premise devient une option stratégique lorsque les données sont sensibles, que la latence doit rester minimale, que l’inférence est continue ou que les contraintes réglementaires limitent l’externalisation. Une architecture hybride reste souvent le meilleur compromis selon les usages.
Quels cas d’usage bénéficient le plus d’une IA locale ?
L’IA locale convient particulièrement aux secteurs bancaire, santé, administration, industrie et télécommunications. Ces environnements manipulent des données critiques, nécessitent une faible latence ou fonctionnent sur des sites éloignés où une dépendance permanente au cloud reste difficile.
Comment la souveraineté des données influence-t-elle les choix d’infrastructure ?
La souveraineté des données pousse les organisations à privilégier une infrastructure IA privée lorsque les réglementations imposent un contrôle renforcé des informations sensibles, des transferts internationaux ou des infrastructures critiques. Cette exigence devient un facteur majeur de décision architecturale.
Quels modèles d’IA fonctionnent efficacement sur une infrastructure privée ?
Les modèles ouverts ou open-weight de taille petite à moyenne offrent les meilleurs compromis pour une infrastructure privée. Leur efficacité augmente lorsqu’ils sont associés au RAG, à la quantification et à une couche d’inférence optimisée adaptée aux ressources disponibles.
Quels sont les principaux défis d’une IA on-premise ?
L’IA on-premise exige un investissement important en serveurs GPU, stockage, énergie, refroidissement, sécurité et compétences d’exploitation. La réussite dépend autant de la gouvernance technique et des équipes que du choix des modèles d’intelligence artificielle.
Comment choisir entre cloud, hybride et IA on-premise ?
Le choix d’une architecture IA dépend principalement de la sensibilité des données, des exigences de latence, de la stabilité des charges d’inférence, des compétences internes et du niveau de conformité attendu. Une segmentation des workloads permet généralement d’obtenir le meilleur équilibre.


