

La gestion électronique des documents (GED) doit passer d’un simple archivage au moteur de connaissance intelligent. Face à l’explosion des données, les entreprises cherchent à rendre l’accès aux informations plus intuitif et pertinent. Selon AWS, les entreprises modernes « font face au défi de fournir un accès fluide aux connaissances ». Les technologies de recherche sémantique et d’IA générative sont en train de révolutionner l’organisation et l’utilisation des connaissances internes. Dans ce contexte, la recherche augmentée (RAG, Retrieval-Augmented Generation) apparaît comme la solution clé : elle combine recherche d’information et génération de langage pour fournir des réponses précises, contextualisées et actualisées. En d’autres termes, la RAG permet à une IA de « requêter des sources de données en temps réel pour garantir des résultats précis et pertinents », échappant ainsi aux limites des modèles entraînés sur des données statiques.
Bulletins et analyses récentes soulignent cet enjeu. Par exemple, l’APN Blog d’AWS insiste sur la synergie entre recherche sémantique et IA pour transformer la GED en base de réponses actives. De même, NVIDIA illustre les pipelines RAG dans une infographie détaillée, soulignant l’importance de chaque étape (indexation, requête vectorielle, génération). Ces avancées montrent que la « Recherche intelligente » n’est plus une utopie : en intégrant la RAG, la GED peut devenir un véritable assistant numérique capable de comprendre le contexte des requêtes et d’extraire dynamiquement la réponse attendue.
Qu’est-ce que la RAG et la recherche intelligente ?
La RAG (Retrieval-Augmented Generation) est une technique d’IA qui combine deux capacités majeures : la récupération d’informations (via recherche sémantique et bases de connaissances) et la génération de texte par LLM. Concrètement, lorsqu’un utilisateur pose une question, le système traduit cette requête en vecteur (embedding), recherche les documents les plus pertinents dans un vecteur de connaissances, puis fournit ces fragments de contexte à un modèle de langage avancé (type GPT) qui génère la réponse. Comme l’explique Athento, « la RAG n’est pas uniquement basée sur les données pré-entraînées d’un modèle, mais s’appuie sur des informations spécifiques et actuelles de l’entreprise ». Cette approche garantit des réponses grounded (ancrées dans les sources d’information de l’entreprise), réduisant drastiquement les risques d’« hallucinations » tout en offrant des réponses à jour.
En parallèle, la recherche intelligente améliore la recherche sémantique traditionnelle. Au lieu de simples mots-clés, elle comprend l’intention de l’utilisateur et exploite les techniques NLP (reconnaissance d’entités, vecteurs de similarité, etc.). Par exemple, Google Cloud souligne qu’associer l’IA générative à la recherche d’entreprise permet de créer des systèmes RAG « prêts à l’emploi », simplifiant la gestion de l’ETL, de l’OCR, du morcellement des documents et de l’indexation. Ainsi, la RAG et la recherche intelligente ouvrent la voie à des moteurs de réponses contextuelles : l’utilisateur peut poser des questions en langage naturel et obtenir une réponse synthétisée, avec références aux documents d’entreprise pertinents.
Évolution de la GED à l’ère de l’IA
Jusqu’à récemment, la GED était surtout perçue comme une « bibliothèque numérique sophistiquée ». Les utilisateurs se référaient à des arbres de dossiers et des métadonnées, la recherche se limitant à quelques mots-clés. Cette approche s’avère maintenant obsolète : l’IA permet de transformer chaque document en source dynamique d’information. Archimag note que « les documents, autrefois inertes, deviennent des sources d’information dynamiques, instantanément exploitables » grâce à l’IA. L’entrée manuelle fastidieuse laisse place à l’automatisation intelligente : extraction automatique des données clés, classement contextuel et accès presque immédiat à l’information pertinente.

Pour réussir cette métamorphose, il faut cependant revisiter les fondamentaux du Knowledge Management. Selon une analyse d’Enterprise-Knowledge, l’IA reste peu exploitée sans une solide gouvernance de données et une culture de partage : « malgré l’essor de l’IA, les initiatives de KM butent souvent sur l’absence de capture de connaissances, de taxonomies partagées et de gouvernance ». Concrètement, il est crucial de structurer les contenus (ontologies, thésaurus) et d’établir des processus clairs de validation des données. Ce n’est qu’avec ces bases solides que la recherche intelligente et la RAG pourront livrer tout leur potentiel. Autrement, l’IA risquerait de naviguer dans un océan de données désorganisées, sans cadre commun. Au final, l’intégration de l’IA dans la GED passe par une transformation de la culture documentaire : le système documentaire devient un « assistant stratégique d’aide à la décision », permettant aux entreprises d’extraire des tendances et insights de leurs archives plus efficacement.
RAG : principes et fonctionnement
« le pipeline RAG comporte trois composants essentiels : la récupération, l’augmentation et la génération »
La mise en place d’une solution RAG nécessite une architecture hybride mêlant outils de recherche et IA. Techniquement, le processus se déroule en plusieurs étapes clés :
- Ingestion et indexation : les documents de la GED (PDF, Word, base de données, tickets, etc.) sont découpés (chunking) puis transformés en vecteurs à l’aide d’un modèle d’embedding. Ces vecteurs sont stockés dans une base vectorielle spécialisée (par ex. Pinecone, Milvus, Weaviate) afin d’accélérer les recherches sémantiques.
- Requête et récupération : à la requête de l’utilisateur, son texte est lui aussi vectorisé et comparé aux vecteurs indexés. Les documents les plus proches (en similitude cosinus) sont sélectionnés. On parle de recherche sémantique ou vector retrieval.
- Génération de la réponse : les contenus récupérés servent de contexte additionnel au LLM. Plutôt que de « deviner » à partir de sa formation initiale, le modèle (ex. GPT-4 ou open-source) produit une réponse en se basant explicitement sur ces passages pertinents. Ce mécanisme de RAG « évite à l’IA de se contenter de son entraînement antérieur » et améliore la précision.
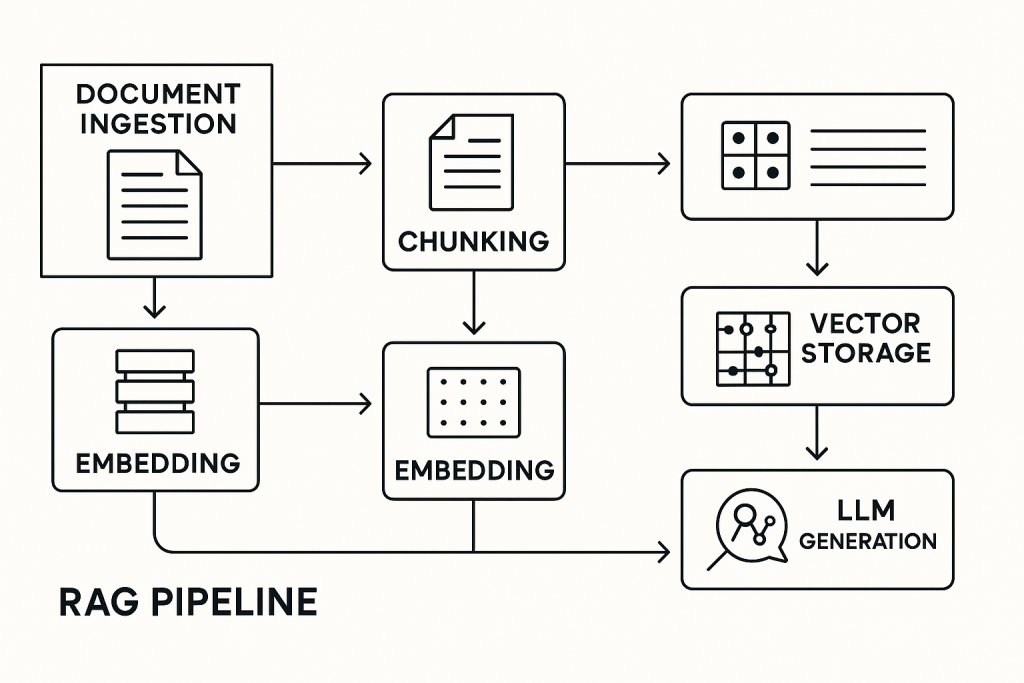
L’illustration ci-dessus schématise un pipeline RAG type (exemple Databricks) : extraction, embedding, stockage en base vectorielle, puis génération via LLM. Outre les technologies standard (OCR, NLP, LLM), des frameworks comme LangChain ou LlamaIndex facilitent la construction de tels flux. Ils offrent des « connecteurs » pour charger des documents variés (bases SQL, wiki, stockage Cloud) et interagir avec différents LLM ou DB de vecteurs. L’objectif est de fluidifier le processus : comme le résume la documentation Databricks, « le pipeline RAG comporte trois composants essentiels : la récupération, l’augmentation et la génération ». En pratique, cette architecture permet d’ancrer en continu les modèles de langage dans la dernière version des données d’entreprise. Par exemple, un chatbot métier interrogeant la GED pourra répondre « aujourd’hui » sans qu’on ait à réentraîner l’IA à chaque mise à jour de document.
Intégration de la RAG dans la GED : étapes et outils
La mise en œuvre pratique d’une RAG sur votre GED implique plusieurs étapes stratégiques et outils spécifiques. Il faut d’abord choisir ou développer une base de connaissances centralisée : cela peut être une collection de documents existants (GED, wiki, forums) ou un graphe de connaissances. Les entreprises commencent souvent par constituer une base de documents indexés (KB) car cela s’intègre plus facilement au contenu non structuré courant. Ensuite, il faut sélectionner des technologies de recherche ; des solutions cloud (Azure AI Search, Amazon Kendra, Google Vertex AI Search) offrent des capacités prêtes à l’emploi pour l’indexation et la recherche vectorielle. Enfin, on intègre un LLM (via une API OpenAI, Anthropic ou un modèle local) pour la génération finale.
Le schéma [55] (Databricks) rappelle ces étapes en entreprise : préparation des données, création d’index de vecteurs, requêtage et inférence LLM. Par exemple, Azure propose un pattern RAG “hors-série” basé sur Azure AI Search et Azure OpenAI, tandis qu’AWS suggère d’enchaîner Textract (OCR) + Kendra (recherche) + Comprehend (NLP) + Bedrock/GPT (génération). Les orchestrateurs modernes (p.ex. LangChain, Semantic Kernel ou RAGatouille) aident à automatiser ces flux. Les bonnes pratiques incluent la segmentation intelligente (chunking) des documents, l’actualisation régulière des index, et la sélection rigoureuse des sources pour nourrir l’IA. Comme le note Astera, sans base de connaissances, l’IA reste « limitée, générique et peu fiable » : la qualité du pipeline RAG dépend ainsi avant tout de la pertinence et de la fraîcheur des données qu’on lui fournit.
Cas d’usage et exemples concrets
Les exemples d’entreprises illustrent la puissance de la RAG sur la GED. Par exemple, l’opérateur télécom Bell a créé un chatbot interne sur RAG pour rendre ses politiques d’entreprise interrogeables en langage nature. Son système met à jour automatiquement l’index dès qu’un document est modifié, garantissant aux employés des réponses à jour sur la conformité et les processus internes. De même, Thomson Reuters a développé une interface conversationnelle pour l’assistance clientèle : les documents d’aide sont découpés en morceaux, indexés en vecteurs, puis les réponses sont générées en combinant ces fragments avec un modèle seq-to-seq. Résultat : le support fournit des réponses précises, argumentées et actualisées sans nécessiter de formation AI spécifique à chaque mise à jour.

D’autres secteurs exploitent la RAG : par exemple, des plateformes vidéo comme Vimeo proposent un système de résumé intelligent (Q&A multimodal) en indexant automatiquement le contenu audio/vidéo pour être interrogable. Grab (super-app asiatique) l’utilise pour automatiser des rapports d’analyse complexe, et LinkedIn intègre la RAG à son graphe de connaissances pour améliorer la recherche interne. Ces cas montrent que tous les départements (R&D, support, RH, finance) peuvent bénéficier d’une recherche intelligente. Les gains sont énormes : support plus réactif, prise de décision accélérée, réduction du travail manuel.
Défis et bonnes pratiques
La mise en place d’une RAG efficace sur une GED présente aussi des défis. Tout d’abord, la qualité des données est cruciale : un contenu désordonné ou incomplet mènera l’IA à des réponses erronées. Il faut donc appliquer des politiques de gouvernance spécifiques à la RAG, comme le souligne Enterprise-Knowledge. Un cadre de gouvernance garantit que les données utilisées sont « accusées d’être précises, actuelles et bien structurées ». Par exemple, on devra mettre en place des processus de validation, de mise à jour continue des index et des métadonnées claires pour chaque document.
Ensuite, l’infrastructure technique peut être coûteuse : l’inférence LLM et le stockage de vecteurs sont gourmands en ressources. Des optimisations (dimensionnalité des vecteurs, filtrage initial de corpus, modèles quantifiés) sont souvent nécessaires. Enfin, la confidentialité et la sécurité sont primordiales : on veillera à ce que les documents sensibles soient traités en local ou chiffrés, et que seules les personnes autorisées puissent interroger certaines catégories d’informations.
Parmi les meilleures pratiques recommandées : commencer par un projet pilote restreint (par service ou cas d’usage), impliquer les métiers dans la définition des requêtes types, et mesurer systématiquement l’amélioration (par exemple en comparant les réponses RAG vs. anciennes requêtes). Comme l’écrit Astera, le cœur de la RAG est la base de connaissances : sans contenu « à récupérer », on retombe sur une IA classique hallucinatoire. Inversement, lorsque ces conditions sont réunies, la RAG offre « des réponses contextualisées, alignées sur l’expertise de l’organisation et actualisées en temps réel », transformant durablement le fonctionnement de la GED.

En conclusion, la recherche intelligente associée à la RAG métamorphose la GED en un véritable moteur de réponse contextuelle. Les documents ne sont plus passifs : ils alimentent un système capable de dialoguer avec l’utilisateur, d’anticiper ses besoins et de lui fournir une réponse argumentée. Pour réussir ce virage, les entreprises doivent combiner expertise métier, gouvernance robuste et technologies adaptées. En investissant dans ces axes, elles gagneront en productivité et en agilité : chaque collaborateur devient alors autonome dans l’accès aux savoirs internes. Envie d’en savoir plus ou de lancer votre projet RAG ? Contactez nos experts pour transformer votre GED et rester à la pointe de l’IA contextuelle.
Contactez-nous pour plus d’information.


